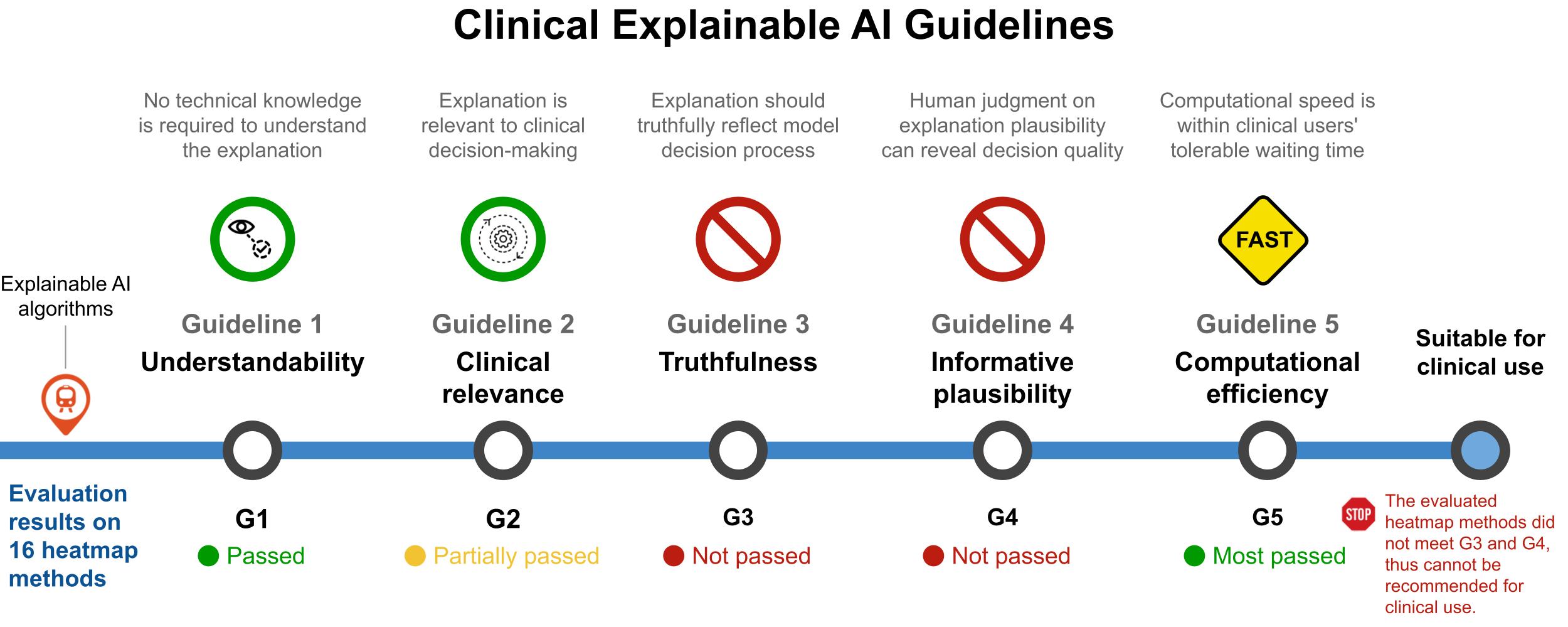
TLDR: The Clinical XAI Guidelines provides criteria that explanation should fulfill in critical decision support.
Explainable artificial intelligence (XAI) is essential for enabling clinical users to get informed decision support from AI and comply with evidence-based medical practice. Applying XAI in clinical settings requires proper evaluation criteria to ensure the explanation technique is both technically sound and clinically useful, but specific support is lacking to achieve this goal. To bridge the research gap, we propose the Clinical XAI Guidelines that consist of five criteria a clinical XAI needs to be optimized for. The guidelines recommend choosing an explanation form based on Guideline 1 (G1) Understandability and G2 Clinical relevance. For the chosen explanation form, its specific XAI technique should be optimized for G3 Truthfulness, G4 Informative plausibility, and G5 Computational efficiency. Following the guidelines, we conducted a systematic evaluation on a novel problem of multi-modal medical image explanation with two clinical tasks, and proposed new evaluation metrics accordingly. Sixteen commonly-used heatmap XAI techniques were evaluated and found to be insufficient for clinical use due to their failure in G3 and G4. Our evaluation demonstrated the use of Clinical XAI Guidelines to support the design and evaluation of clinically viable XAI.
@article{JIN2023102684,title={Guidelines and evaluation of clinical explainable AI in medical image analysis},journal={Medical Image Analysis},volume={84},pages={102684},year={2023},issn={1361-8415},doi={https://doi.org/10.1016/j.media.2022.102684},url={https://www.sciencedirect.com/science/article/pii/S1361841522003127},author={Jin, Weina and Li, Xiaoxiao and Fatehi, Mostafa and Hamarneh, Ghassan},keywords={Interpretable machine learning, Medical image analysis, Multi-modal medical image, Explainable AI evaluation},project={xai_eval},}
MethodsX
Generating post-hoc explanation from deep neural networks for multi-modal medical image analysis tasks
Jin, Weina, Li, Xiaoxiao, Fatehi, Mostafa, and Hamarneh, Ghassan
TLDR: Describing the methods of generating AI heatmap explanations for multi-modal medical images.
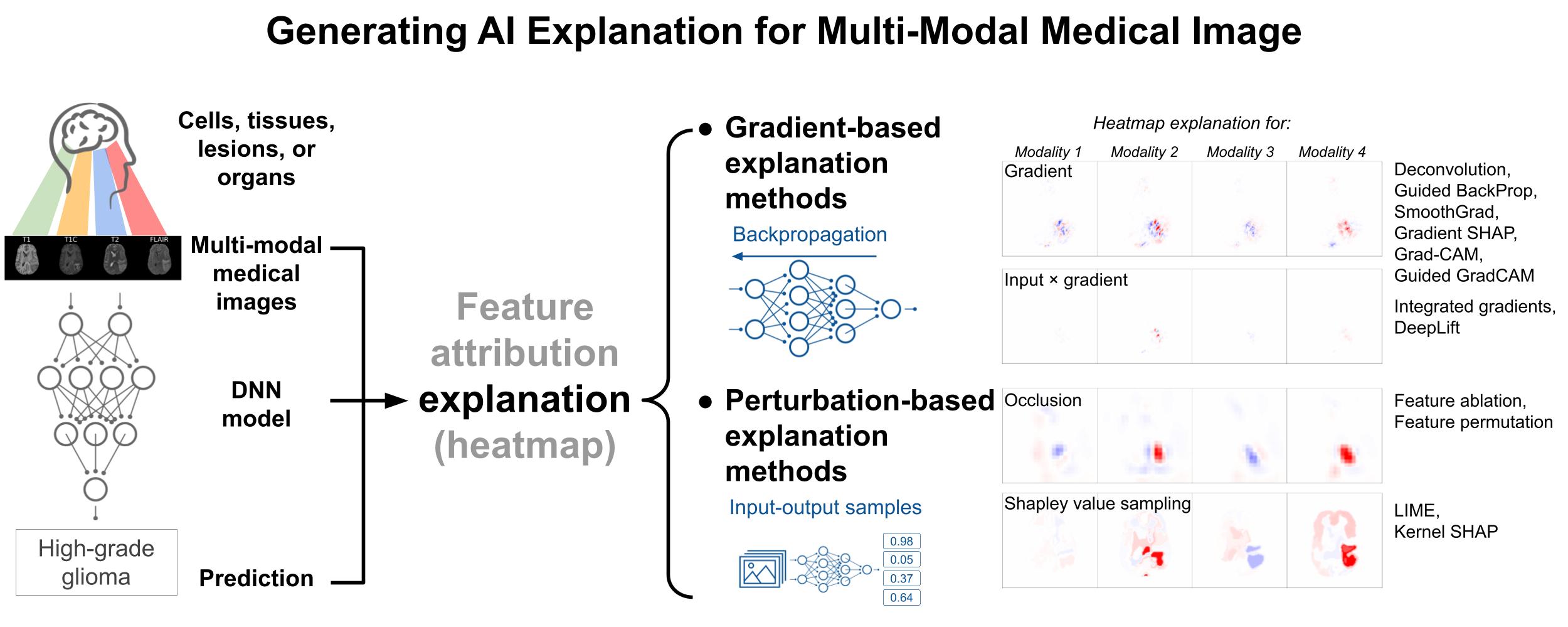
Explaining model decisions from medical image inputs is necessary for deploying deep neural network (DNN) based models as clinical decision assistants. The acquisition of multi-modal medical images is pervasive in practice for supporting the clinical decision-making process. Multi-modal images capture different aspects of the same underlying regions of interest. Explaining DNN decisions on multi-modal medical images is thus a clinically important problem. Our methods adopt commonly-used post-hoc artificial intelligence feature attribution methods to explain DNN decisions on multi-modal medical images, including two categories of gradient- and perturbation-based methods. • Gradient-based explanation methods – such as Guided BackProp, DeepLift – utilize the gradient signal to estimate the feature importance for model prediction. • Perturbation-based methods – such as occlusion, LIME, kernel SHAP – utilize the input-output sampling pairs to estimate the feature importance. • We describe the implementation details on how to make the methods work for multi-modal image input, and make the implementation code available.
@article{JIN2023102009,title={Generating post-hoc explanation from deep neural networks for multi-modal medical image analysis tasks},journal={MethodsX},volume={10},pages={102009},year={2023},issn={2215-0161},doi={https://doi.org/10.1016/j.mex.2023.102009},url={https://www.sciencedirect.com/science/article/pii/S2215016123000146},author={Jin, Weina and Li, Xiaoxiao and Fatehi, Mostafa and Hamarneh, Ghassan},keywords={Interpretable machine learning, Explainable artificial intelligence, Medical image analysis, Multi-modal medical image, Post-hoc explanation},project={xai_eval},}
A precursor of this work is published at AAAI 22 Social Impact Track:
Evaluating Explainable AI on a Multi-Modal Medical Imaging Task: Can Existing Algorithms Fulfill Clinical Requirements?
AAAI
Evaluating Explainable AI on a Multi-Modal Medical Imaging Task: Can Existing Algorithms Fulfill Clinical Requirements?
Jin, Weina, Li, Xiaoxiao, and Hamarneh, Ghassan
Proceedings of the AAAI Conference on Artificial Intelligence Jun 2022
TLDR: Our systematic evaluation showed the examined 16 heatmap algorithms failed to fulfill clinical requirements to correctly indicate AI model decision process or decision quality.
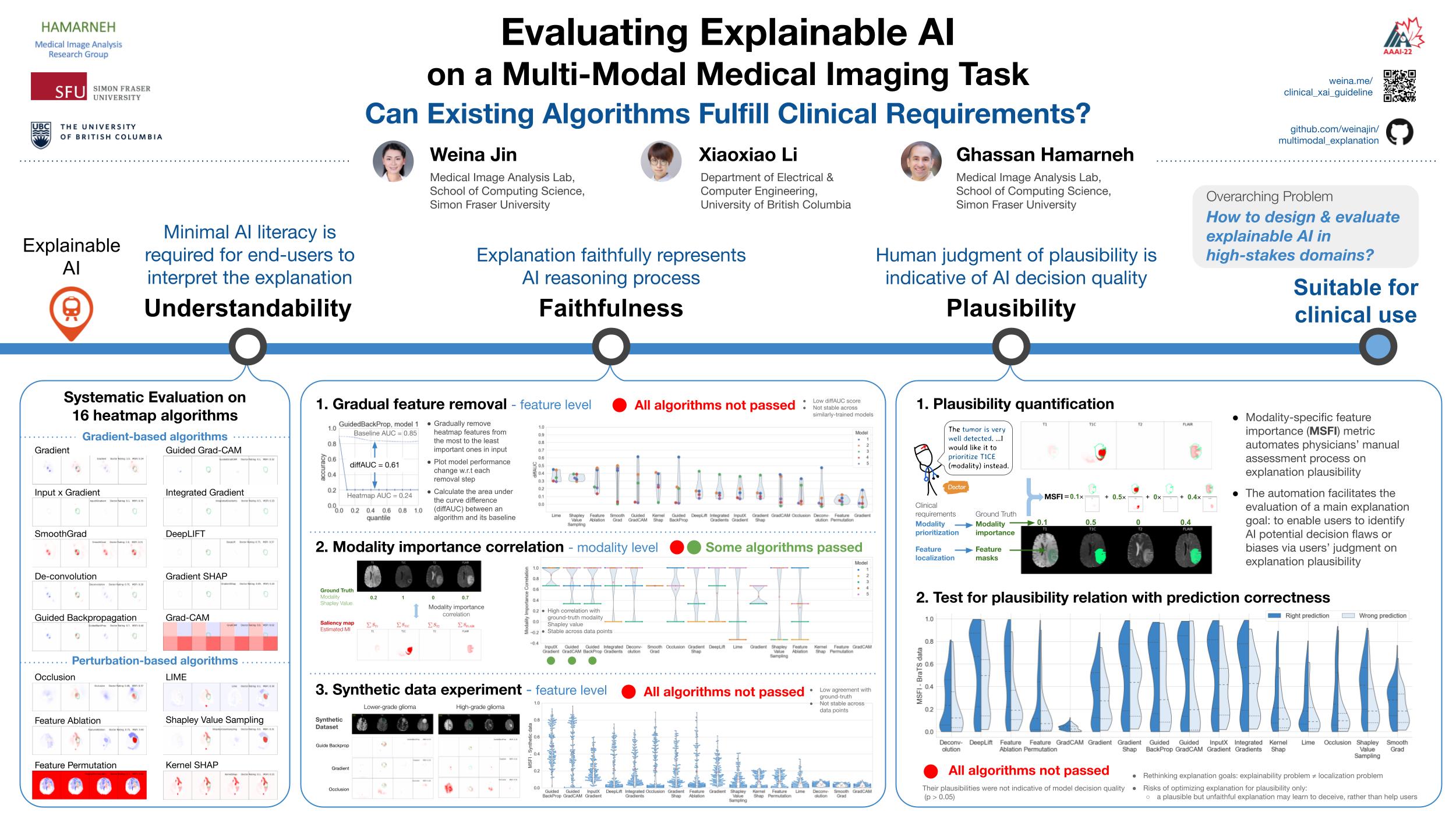
Being able to explain the prediction to clinical end-users is a necessity to leverage the power of artificial intelligence (AI) models for clinical decision support. For medical images, a feature attribution map, or heatmap, is the most common form of explanation that highlights important features for AI models’ prediction. However, it is unknown how well heatmaps perform on explaining decisions on multi-modal medical images, where each image modality or channel visualizes distinct clinical information of the same underlying biomedical phenomenon. Understanding such modality-dependent features is essential for clinical users’ interpretation of AI decisions. To tackle this clinically important but technically ignored problem, we propose the modality-specific feature importance (MSFI) metric. It encodes clinical image and explanation interpretation patterns of modality prioritization and modality-specific feature localization. We conduct a clinical requirement-grounded, systematic evaluation using computational methods and a clinician user study. Results show that the examined 16 heatmap algorithms failed to fulfill clinical requirements to correctly indicate AI model decision process or decision quality. The evaluation and MSFI metric can guide the design and selection of explainable AI algorithms to meet clinical requirements on multi-modal explanation.
@article{Jin_Li_Hamarneh_2022,title={Evaluating Explainable AI on a Multi-Modal Medical Imaging Task: Can Existing Algorithms Fulfill Clinical Requirements?},volume={36},url={https://ojs.aaai.org/index.php/AAAI/article/view/21452},doi={10.1609/aaai.v36i11.21452},number={11},journal={Proceedings of the AAAI Conference on Artificial Intelligence},author={Jin, Weina and Li, Xiaoxiao and Hamarneh, Ghassan},year={2022},month=jun,pages={11945-11953},project={xai_eval_aaai},}
The overarching problem is: how to design and evaluate explainable AI in real-world high-stakes domains. We propose a novel problem in the medical domain, multi-modal medical image explanation, and use it as an example to demonstrate our evaluation process that incorporates both technical and clinical requirements.
Our evaluation is on the commonly used heatmap methods for end-user understandability. We cover both gradient and perturbation-based methods.
Based on the explanation goals in real-world critical tasks, we set two primary evaluation objectives on faithfulness and plausibility. Three evaluations on faithfulness show all the examined algorithms did not faithfully represent the AI model decision process at feature level. And plausibility evaluation results show that users’ assessment of how plausible explanations are, is not indicative for model decision quality.
Our systematic evaluation provides a roadmap and objectives for the design and evaluation of explainable AI in critical tasks.
TLDR: The precursor of the AAAI22’ paper - Evaluating Explainable AI on a Multi-Modal Medical Imaging Task: Can Existing Algorithms Fulfill Clinical Requirements?
Being able to explain the prediction to clinical end-users is a necessity to leverage the power of AI models for clinical decision support. For medical images, saliency maps are the most common form of explanation. The maps highlight important features for AI model’s prediction. Although many saliency map methods have been proposed, it is unknown how well they perform on explaining decisions on multi-modal medical images, where each modality/channel carries distinct clinical meanings of the same underlying biomedical phenomenon. Understanding such modality-dependent features is essential for clinical users’ interpretation of AI decisions. To tackle this clinically important but technically ignored problem, we propose the MSFI (Modality-Specific Feature Importance) metric to examine whether saliency maps can highlight modality-specific important features. MSFI encodes the clinical requirements on modality prioritization and modality-specific feature localization. Our evaluations on 16 commonly used saliency map methods, including a clinician user study, show that although most saliency map methods captured modality importance information in general, most of them failed to highlight modality-specific important features consistently and precisely. The evaluation results guide the choices of saliency map methods and provide insights to propose new ones targeting clinical applications.
@article{jin2021one_map_not_fit_all,author={Jin, Weina and Li, Xiaoxiao and Hamarneh, Ghassan},title={One Map Does Not Fit All: Evaluating Saliency Map Explanation on Multi-Modal
Medical Images},journal={ICML 2021 Workshop on Interpretable Machine Learning in Healthcare},year={2021},eprinttype={arXiv},eprint={2107.05047},timestamp={Tue, 20 Jul 2021 15:08:33 +0200},biburl={https://dblp.org/rec/journals/corr/abs-2107-05047.bib},bibsource={dblp computer science bibliography, https://dblp.org},project={one_map},}



{kind=link}